
A Short Review of Scholarly Network Approahces to Modeling the Structure of Knowledge Domains
Table of Contents
Introduction
How knowledge is created, structured, and developed have been fundamental questions in humanities and social sciences. Knowledge’s ever-growing amount and complexity call for a holistic approach to understanding the development of multi-disciplinary academics and the synthesis of concepts, theories, and methods. Scholarly networks, built from academic metadata, have proved powerful tools in these tasks. Its nodes usually denotes academic entities (concept, paper, venue, researcher, institution, etc.) and links represent relationships such as citation, co-authorship, or co-word. [1]
This paper aims to provide an in-depth review of the scholarly network-based approaches in knowledge modeling and discovery. The comparison will be conducted from three perspectives: (1) how the networks are constructed, including the link weight measurement and node aggregation, (2) levels of network-based approaches, and (3) research purposes to be achieved by these approaches. Finally, it will discuss the advantages and limitations of using scholarly networks.
Comparison of Scholarly Network-based Approaches
Researchers have developed various methods to construct and apply scholarly networks with decisions on what entity to take as node, what relationship to map, and on which level the information is aggregated.
Major types of scholarly networks include co-authorship network (scholars collaborate with each other), citation network (publications referencing each other), co-citation network (publications cited by same documents), bibliographic coupling network (publications having similar bibliographies), co-word network (word concurring), topical network (document level topic modeling), and heterogeneous network (multiple types of academic units and relationships). [2]
Link Construction
I categorize these major scholarly networks into several simple categories based on how their links are constructed (see Table 1 and Figure 1).
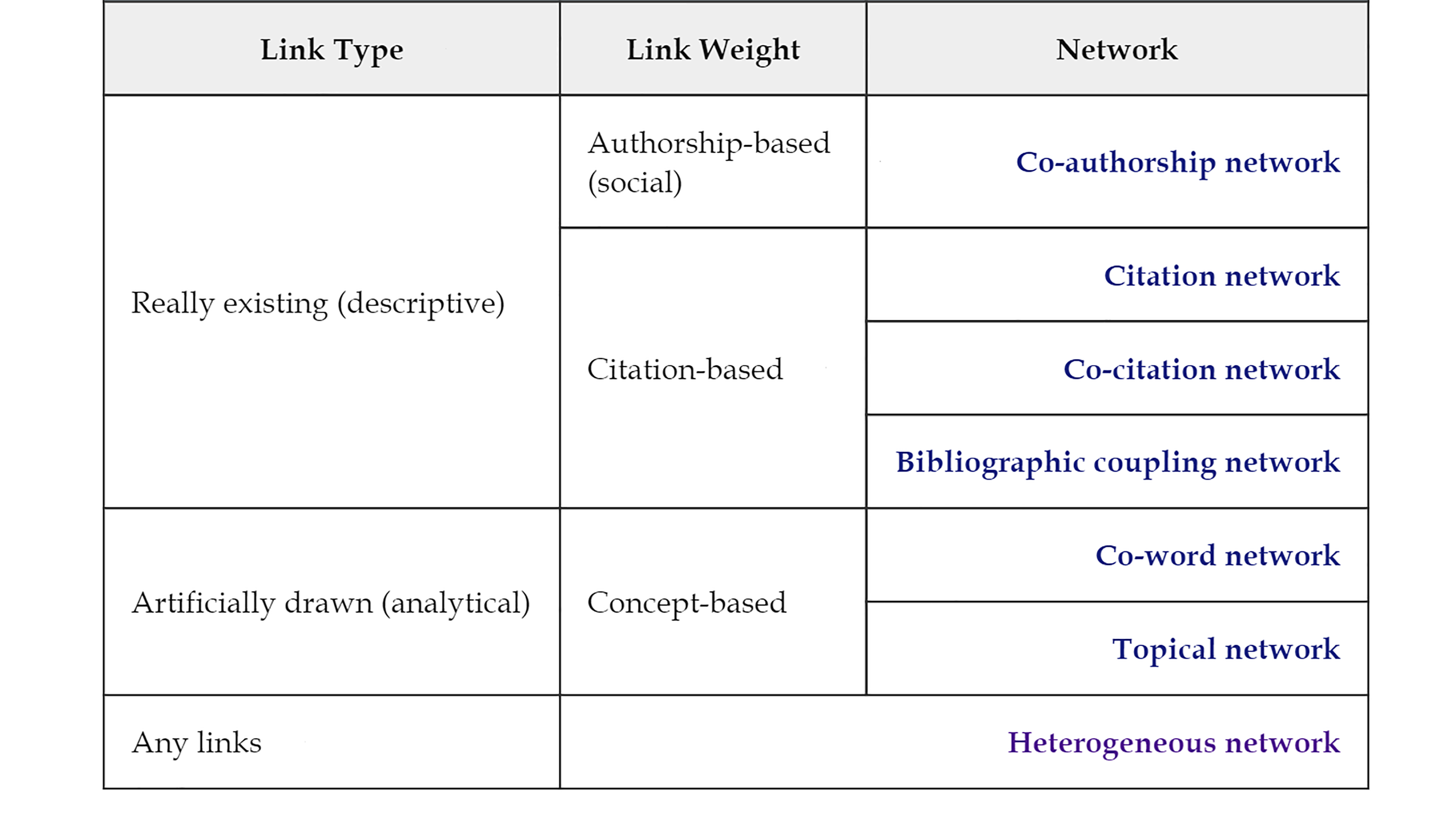
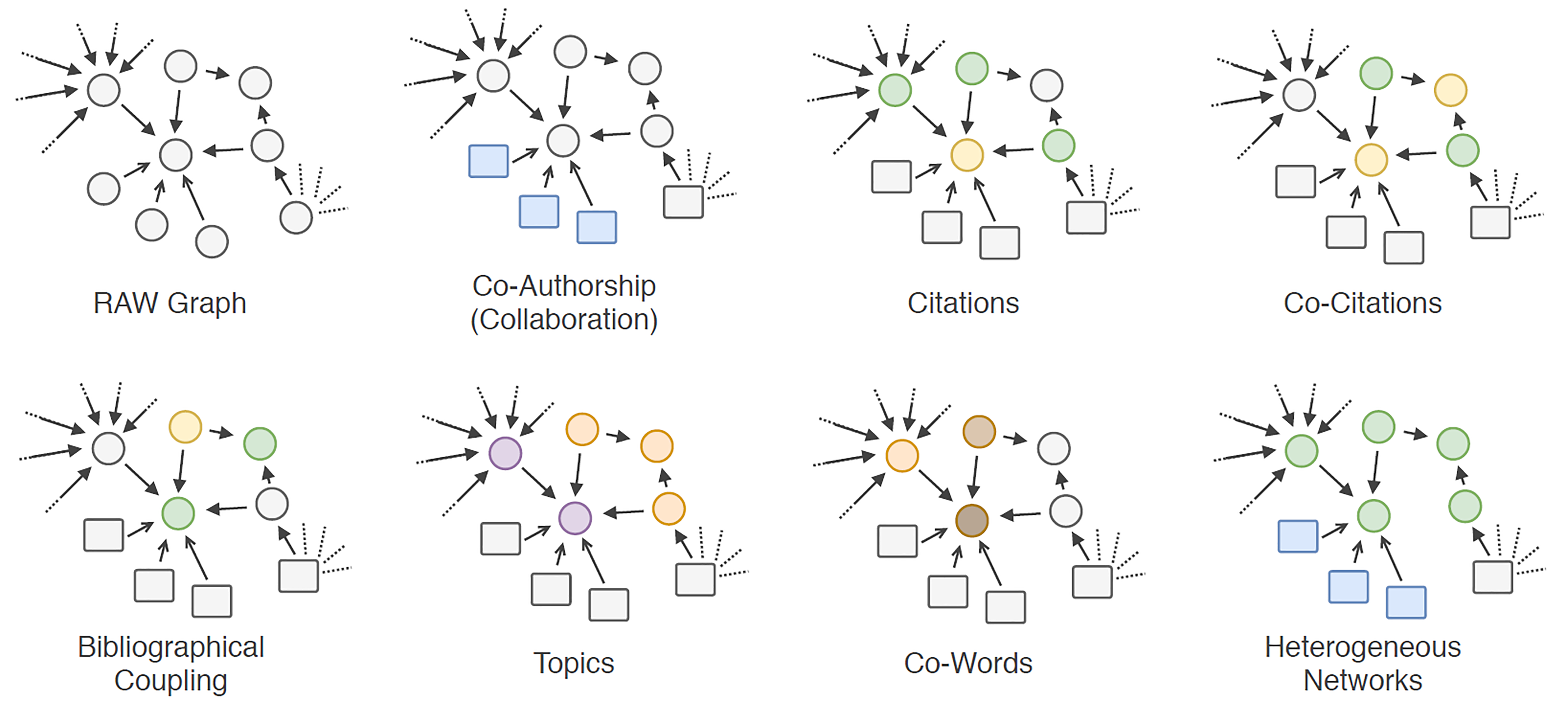
Some networks are more descriptive, describing connections that really exist, such as citations and authorship. Typical networks are co-authorship network, citation network, co-citation network, and bibliographic coupling network, which measure link weights based on co-authorship or citation counts.
- Co-authorship network. The links indicate academic collaboration based on the co-authorship of researchers on publications, and their weights denote the number of co-authored publications of certain researchers.
- Citation and co-citation network. They describe relationships between cited papers and papers that cite those papers. [4]
- Bibliographic coupling network. Its links indicate the similarity between the bibliographies of two documents, whose strengths depend on the number of common third cited work they refer to.
Contrary to these descriptive, “real” networks, analytical networks map connections that are artificially designed and drawn by researchers and thus inherently contain presumptions of the links.
- Co-word network. Links are constructed between documents that share the same keywords in the abstract or title, and the weights are the co-occurrence of key-words. [5]
- Topical network. Its link quantifies the topic similarity between nodes, where topics are extracted using topic modeling and link strengths is the probability of being on the same research topic.
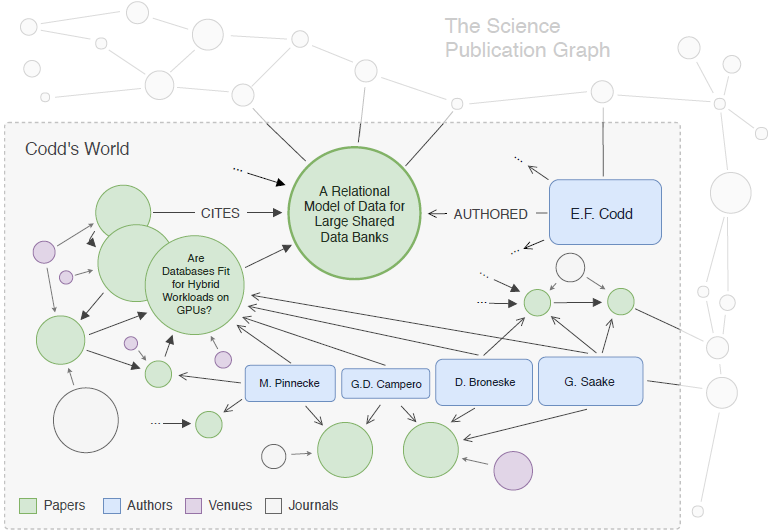
The citation-based, authorship-based, and concept-based networks are all homogeneous networks, in which only one type of node and link exists. While the reality is far more complicated—the networks of academic entities are usually linked by more than one relation. Thus, heterogeneous networks were introduced, which enables any diversity of nodes and relations. Take the Codd’s World academic network as an example (figure 2).
Node Aggregation Level
The nodes in scholarly networks are academic entities, including concept, paper, venue, researcher, institution, and field (within or across disciplines). These entities are on different levels. The most basic academic unit is a single concept or paper, and basic units can be aggregated to higher levels, such as venue units or field units. The aggregation levels of nodes provide multiple focus lenses that allow us to zoom in and zoom out to gain concrete or holistic views on academic research discourses. [1]
Even the links are constructed in the same way, scholarly networks with different node aggregation levels offer diverging perspectives and insights. Take paper, author, and journal co-citation networks as examples. The paper-level co-citation network is the most standard approach, which clusters and helps to identify research topics. [6] If the nodes are aggregated at the author level, co-citation networks are used to reveal the structure of academic communities as well as the scholar’s influence. [7] If the nodes are chosen as journals, co-citation networks show the knowledge diffusion among research domains. [8]
Research Purposes and Levels of Network-based Approaches
The previous discussion covers the construction of scholarly networks, but networks, as tools, are not the essential part of the research. What matters the most are the research purposes and the corresponding approaches adopted, i.e., how researchers use network tools to answer knowledge-related questions. Research purposes can be categorized into four types: to evaluate, to model, to predict, and to visualize academic entities, their interactions, or their structure patterns.
-
Knowledge/knowledge producer evaluation: Design bibliometric and scientometric indexes to evaluate the influence, significance, or other characteristics of academic entities and thus to identify other entities with similar patterns, such as to find key opinion leaders with co-authorship network analysis. [9]
-
Knowledge modeling: Model the knowledge dynamics (transfer and diffusion), academic discourse (emergence and development), and its underlying structure. For instance, using co-word analysis to identify connected topics and subjects to trace the development of a research field. [5]
-
Knowledge prediction: Utilize summarized pattern to predict new connections, entities features, or subgraph structures, thus promoting innovation and interdisciplinarity.[11] [9]
-
Knowledge visualization: Visualize knowledge in networks to facilitate knowledge navigation and discovery.
In research with the first three purposes, the adopted scholarly network-based approaches also vary in terms of levels. At the micro-level, bibliometric indicators are created to evaluate and rank the significance of nodes (academic entities). The link is the focus of meso-level approaches, where clustering algorithms are performed to identify key topics, and prediction models are used to predict possible relationships between entities. [11] The macro-level network-based approaches produce global statistics of graphs or subgraphs that demonstrate general patterns of knowledge development and underlying structures.[12]
Advantages and limitations of Networks
The network-based approach has two cutting edges over traditional methods. The first one is its ability to deal with a vast number of documents, provide a large-scale perspective on the development and patterns in disciplines. [13] It thus enables the recognition of highlight features of scientific fields that are widely neglected due to bias. [5] Another advantage of network-based approaches lies in the networked structure. In quantitative scientific evaluation, simple citation counting, though has been used for several decades, was criticized for ignoring the linking structure of citing journals, authors, and papers. Thus, multiple network-based bibliometric indicators are introduced, which take into account the citation endorsement, such as P-Rank. [14]
Though it is tempting to apply network methods on everything that seems connected, the limitations of network approaches cannot be overlooked. One thing worth noting is that network is just one way to represent knowledge and the choices of knowledge representation should be built on the understanding of the embedded data structure and what questions are being asked. Furthermore, when applying scholarly network-based approaches, task-specific interpretive frameworks need to be developed and fine-tuned. Concepts and algorithms in network analysis may work well in a specific domain or task but performs poorly on another. For instance, betweenness centrality is an effective indicator of interdisciplinarity, while closeness centrality is not an appropriate indicator of multidisciplinarity. [15]
A list of updated resources on scholarly matadata

Bibliographies
[1] Yan, Erjia, and Ying Ding. “Scholarly network similarities: How bibliographic coupling networks, citation networks, cocitation networks, topical networks, coauthorship net- works, and coword networks relate to each other.” Journal of the American Society for Information Science and Technology 63 (2012): 1313–1326. https://doi.org/10. 1002/asi.22680.
[2] Erjia Yan, 2014. “Finding knowledge paths among scientific disciplines,” Journal of the Association for Information Science & Technology, Association for Information Science & Technology, vol. 65(11), pages 2331-2347, November.
[3] Pawar, R.S., Sobhgol, S., Durand, G.C., Pinnecke, M., Broneske, D. and Saake, G., 2019. Codd’s World: Topics and their Evolution in the Database Community Publication Graph. In Grundlagen von Datenbanken (pp. 74–81).
[4] Small, Henry. “Co-citation in the scientific literature: A new measure of the relationship between two documents.” Journal of the American Society for Information Science 24 (July 1973): 265–269. https://doi.org/10.1002/asi.4630240406.
[5] He, Qin. “Knowledge Discovery Through Co-Word Analysis,” 1999. http://hdl.handle.net/ 2142/8267.
[6] Boyack, Kevin W., and Richard Klavans. “Co-citation analysis, bibliographic coupling, and direct citation: Which citation approach represents the research front most accurately?” Journal of the American Society for Information Science and Technology 61 (December 2010): 2389–2404. Accessed April 16, 2020. https://doi.org/10.1002/asi.21419.
[7] Chen, Chaomei. “Visualising semantic spaces and author cocitation networks in digital libraries.” Information Processing Management, 1999, 401–420. https://doi.org/10. 1016/s03064573(98)000685.
[8] Ding, Ying, Gobinda G. Chowdhury, and Schubert Foo. “Journal as markers of intellectual space: Journal cocitation analysis of information retrieval area, 1987–1997.” Sciento- metrics 47 (2000): 55–73. Accessed November 16, 2020. https://doi.org/10.1023/a:1005665709109.
[9] Grodzinski, Noah, Ben Grodzinski, and Benjamin M. Davies. “Can co-authorship net- works be used to predict author research impact? A machine-learning based analysis within the field of degenerative cervical myelopathy research.” Edited by Michael G. Fehlings. PLOS ONE 16 (September 2021): e0256997. Accessed February 10, 2022. https://doi.org/10.1371/journal.pone.0256997.
[11] Sun, Yizhou, Rick Barber, Manish Gupta, Charu C. Aggarwal, and Jiawei Han. “Co- author Relationship Prediction in Heterogeneous Bibliographic Networks,” July 2011. Accessed March 20, 2022. https://doi.org/10.1109/asonam.2011.112.
[12] Rafols, Ismael, and Martin Meyer. “Diversity and network coherence as indicators of inter- disciplinarity: case studies in bionanoscience.” Scientometrics 82 (June 2009): 263–287. Accessed February 13, 2022. https://doi.org/10.1007/s11192-009-0041-y.
[13] Feng, Shihui, and Alec Kirkley. “Mixing Patterns in Interdisciplinary Co-Authorship Net- works at Multiple Scales.” Scientific Reports 10 (May 2020). Accessed August 25, 2020. https://doi.org/10.1038/s41598-020-64351-3.
[14] Yan, Erjia, Ying Ding, and Cassidy R Sugimoto. “PRank: An indicator measuring prestige in heterogeneous scholarly networks.” Journal of the American Society for Information Science and Technology 62 (2010): 467–477. https://doi.org/10.1002/asi.21461.
[15] Leydesdorff, Loet. “Betweenness centrality as an indicator of the interdisciplinarity of sci- entific journals.” Journal of the American Society for Information Science and Tech- nology 58 (2007): 1303–1319. Accessed March 15, 2020. https://doi.org/10.1002/asi.20614.